
中国报道讯(通讯员 周聪)在之前的文章《技术干货:人大金仓KFS精准过滤和分片并行入库技术解析》中,KFS利用分片并行入库技术,解决了某金融POC数据同步项目中数据入库持续积压问题。经过优化后,在200并发的压测场景中,整体同步性能指标从压测30分钟延迟10-20分钟,变为准实时同步,延迟2秒以内。
分片并行入库技术的核心原理是将原本需要顺序入库的数据,以事务为单位进行拆分,然后并行入库。

引入分片并行入库特性后的入库逻辑

举例:在原本单车道的路上,每辆汽车载客一人,为了提高通行效率修建为双车道或者多车道(双车道的目的地是同一个城市的不同站),将汽车按照随机或者轮询的方式分配到不同的车道上,从而提高通行效率。
但在另外一个金融项目中,由于客户的业务逻辑非常复杂,数据库表之间的关联盘根错节,为了配置“分片并行入库”,现场人员耗费了几天时间在表关联的梳理上。然而在成功配置“分片并行入库”方案后,整体的同步性能依然无法满足客户诉求。
问题深度定位
分片并行入库方案中,为了解决数据一致性问题,引入了Critical数据区的概念。在复杂的数据同步场景中,对整体性能和易用性带来了比较大的冲击。
“Critical数据区”的性能瓶颈
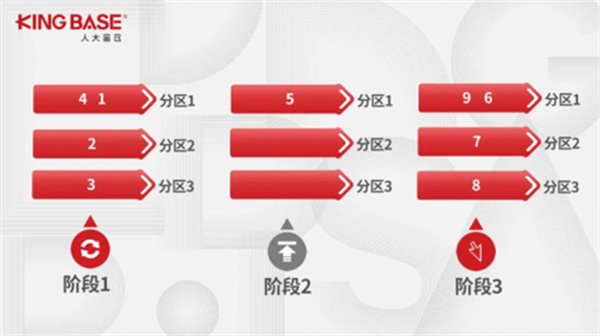
KFS“Critical数据区”把需要处理具有多表关联事务的表标记为“Critical”,当处理“Critical”表的事务数据时,需要保证数据串行入库。比如下图所示的9个事务,假设每个事务入库需要1秒,如果使用3个通道并行入库,在不考虑数据有序性的情况下每个通道平均分得3个事务,总共需要3秒执行完成。

但是,如果表D被标记为“Critical”,处理所有事务就需要分为三个阶段:
阶段一:在处理事务5前,要等待所有通道中的数据处理完成;
阶段二:串行处理事务5,此时退化成单通道模型;
阶段三:事务5处理完成后,恢复成多通道模型,并行处理事务6~9。
举例:将“Critical”表事务比喻成一辆大货车,普通表事务比喻成一辆小轿车,在通过一个三车道的隧道时,普通小轿车可以并行通过,但是一旦大货车过此隧道时,整个隧道就只能允许大货车单独通过,并且在大货车进入隧道中时设置等待指示,不允许小轿车进入。等待大货车出隧道后,才允许小轿车并行通过。
上述整个事务处理中,事务1~4分3个通道并行处理,需要2次共耗时2秒,处理事务5单独耗时1秒,事务6~9分3个通道并行处理,需要2次共耗时2秒。所以整体耗时5秒,相比无“Critical”时耗时增加了60%。
实际上现场业务相对复杂,“Critical”表的事务频繁出现,导致了数据入库时并行和串行交替切换,即使配置了“分片并行入库”方案,性能提升效果也不好。
复杂业务场景中的新问题
引入分片并行入库技术后,KFS在应付简单业务的数据同步压测场景中游刃有余,但是在实际的复杂业务中还存在一些问题,比如:
对同一张表的同一行数据先后做不同的操作可能引起数据不一致,例如:
事务1:将表1中key=1数据的key修改为2
事务2:将表1中key=2数据的key修改为3
如果两个事务被分配在不同分片中,就有可能出现事务2先执行导致最终数据修改失败。
举例:车队中有两辆车的乘客是一家人,并且希望父母和孩子能够在同一个车道到到达同一个站点,由先到站的父母带着后到站的孩子一起去旅行。如果这两辆车没有被分配到一个车道,就有可能导致孩子先到站并且后续父母和孩子没有到达一个站点,导致孩子无人接收,发生孩子丢失的悲剧。
多表关联交叉事务如果分配在不同通道同时执行,可能产生死锁。
举例:车队中有两辆车分别有2位乘客,前面一辆车的的乘客为A孩子的父亲和B孩子;后面一辆车的乘客为B孩子的父亲和A孩子;原本计划到站后互相交换孩子,继续各自的旅程。如果这两辆车没有被分配到一个车道,就会出现两个父亲互相带着别人的孩子在错误的站点等待自己孩子的情形,谁也无法将孩子交还给对方,谁也无法领回自己的孩子。
具有外键约束的表,如果分配在不同通道执行,可能产生数据入库异常。比如针对主外键依赖的两张表,总是希望被依赖表中的数据先插入,依赖表的数据后插入,才能不违反外键约束。如果有外键约束的两张表分配在不同通道,就可能导致依赖表的数据先插入,从而引发数据入库报错。
举例:车队中有两辆车的乘客是一家人,并且希望父母先到,孩子后到,由先到站的父母带着后到站的孩子一起去旅行。如果这两辆车没有被分配到一个车道,就有可能导致孩子先到站无人接收,发生孩子丢失的悲剧。
由单通道改为多通道后,原本需要串行执行的事务被人为的并行起来。多个通道执行数据入库的性能不同,多分区如何记录断点,以及分区断点恢复也是一个棘手问题。
实战演练,终结行业痛点
针对以上问题,KFS 引入了“基于分区索引分片入库”方案,在完美解决以上问题的前提下,相较于无差别分片并行入库还没有性能损失。
以下我们将通过实际测试结果来验证在不同场景下“基于分区索引分片入库”方案和其他方案的性能差异。
模拟测试场景中的效果
测试模型
在数据库中建立5张表,使用Jmeter工具并行压测不同的事务数据,分别测试以下几种场景的性能:
多表纯INSERT开启和关闭分片并行入库的性能对比;
多表混合事务开启和关闭分片并行入库的性能对比;
测试环境
硬件:X86、8核CPU、16GB内存、1TB NVME硬盘
操作系统:CentOS 7.6
JDK:1.8
KES版本:V8R6
测试结果
多表INSERT事务场景下入库性能对比
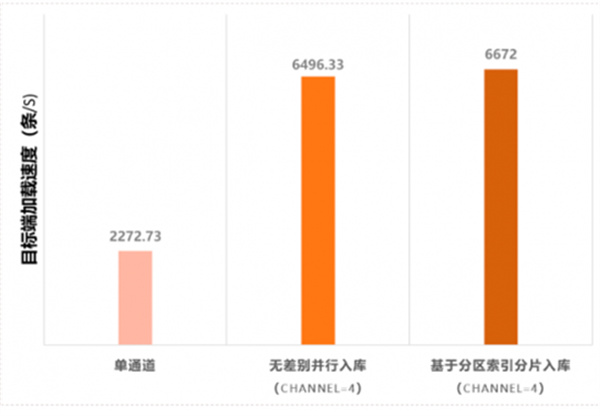
张表并发插入10万条insert数据(一条insert一个事务),可以看到纯INSERT小事务模型下,新引入的“基于分区索引分片入库”方案和之前无差别“分片并行入库”方案性能基本持平,相比较原始的单线程入库性能提升到3倍左右。
多表混合事务场景下入库性能对比
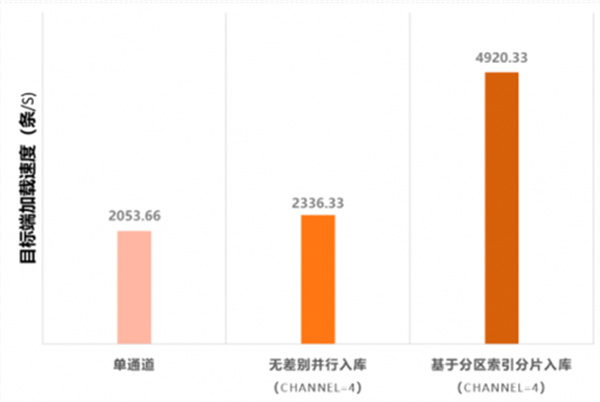
5张表并发执行增、删、改操作(约包含18%比例的多表混合事务,混合事务中包含1至5条SQL),合计50万条数据,可以看到由于多表混合事务的影响,之前无差别“分片并行入库”方案性能较原始的单线程入库性能已无多少优势,而新引入的“基于分区索引分片入库”方案较比原始的单线程入库性能提升到2.4倍左右。
总结
“基于分区索引分片入库”方案,可以在不损失无差别分片并行入库方案性能的前提下,弥补无差别分片并行入库方案的缺陷。
客户问题解决效果
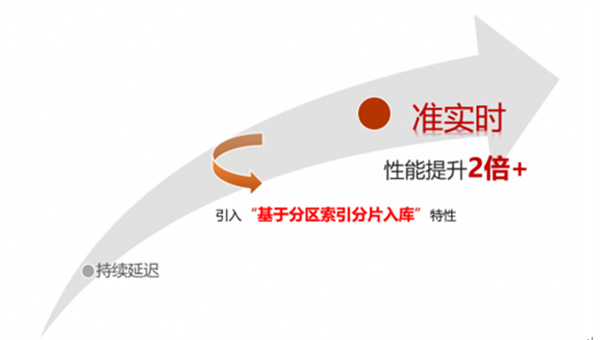
在配置了“基于分区索引分片入库”方案后,实际业务场景的表现效果和模拟测试基本一致,开启4通道并行入库后,入库性能基本达到了单通道的2倍多,原先的并发24小时业务延迟持续拉大,变为了准实时同步。
极致性能背后的黑科技
关键技术 基于分区索引分片入库方案
引入Critical数据区概念的分片并行入库技术最大的问题是需要预先清楚业务场景,才能将正确的表放入Critical数据区中。针对实际业务动态变化的场景,可能出现因配置遗漏导致数据不一致性。本次,我们使用了一种基于分区索引自动分区的关键技术,在不降低性能的前提下,很好的解决了这些问题。
使用分区索引来指导事务分片
自动分区技术解决的关键问题是:维护未提交事务的信息。其核心原理为:分发事务时,根据分区索引确认分发的具体通道,最大限度的减少触发Critical数据区。
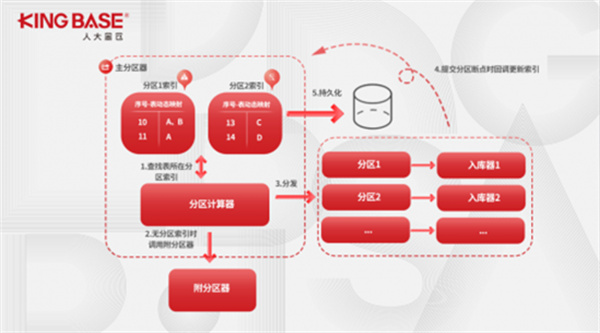
分区索引中仅记录了未提交的事务。数据同步过程中存在相互依赖的事务和总事务数量比起来,占比很小。
因此仅需要很小的内存空间,就解决掉了使用“Critical数据区的分片并行入库技术”中存在的需要客户自行配置Critical表的易用性问题。使分片并行入库技术向产品化更进了一步。
使用分区屏障来解决分区失效问题
分区索引方案中当入库器写数据库速度不足(比如数据库性能瓶颈)时,一旦出现多表关联事件,会导致后续事件全部发送到同一分区,从而引发多分区机制的失效
为了解决多分区失效问题,又配套引入分区屏障机制,当某个分区队列满时,对此分区设置一个屏障,后续准备发送到此分区的数据暂时阻塞。入库器在写出事务,更新分区索引时,会自动检查当前分区的使用容量,如果使用容量小于某阈值(例如50%),则移除此分区上的屏障,允许后续事务被分发至次分区。
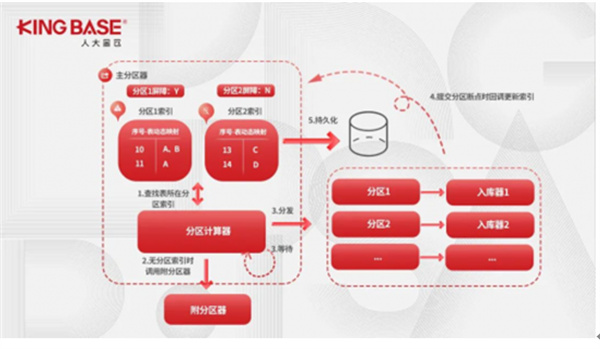
使用了分区屏障机制后,有效解决了数据集中分发至某一分区时导致分区失效的连锁反应。
结语
在使用了分区索引和分区屏障技术后,KFS的并行分区入库技术走向成熟。KFS并行分区入库技术目前已成功被运用到多个关键项目中,帮助客户极大的缩短数据集成时间,提升业务系统的运行效率。
KFS作为一款自主研发的国产数据同步软件,深耕于各种国产化数据改造项目。面对每一次数据同步的性能挑战,奋力创新,更多黑科技已经蓄势待发,让我们拭目以待!
责任编辑:石勇
版权所有 中国外文局亚太传播中心(人民中国杂志社、中国报道杂志社) 广播电视节目制作经营许可证:(京)字第07311号 电子邮件: chinareport@foxmail.com 法律顾问:北京岳成律师事务所
投诉举报电话: 010-68995855 互联网出版许可证:新出网证(京)字 189号 京ICP备14043293号-10 京公网安备:110102000508

